A lo largo de los años se han utilizado redes neuronales para mejorar muchos aspectos de nuestras vidas, sin notarlo, las redes neuronales se introducen en nuestras vidas de distintas formas, una de ellas es al momento de navegar por la web y recibir recomendaciones sobre artículos que nos gustaría comprar, generaciones de texto que se ajusten al estilo de algún autor que admiramos en particular e incluso Modificar el tipo o estilo de arte que queremos para una imagen.
Recientemente existen bastantes tutoriales y cursos sobre cómo generar texto a partir de redes neuronales y bastantes blogs de personas generando cambios de imágenes, entre otras cosas. Un uso novedoso de redes neuronales es la generación de música, de hecho, un ejemplo muy interesante y emocionante sobre esta novedad sería el generador de música de OpenAI, el cual cuenta con dos proyectos: Musenet, el cual genera música instrumental y la clasifica, y Jukebox el más novedoso de los dos y publicado recientemente, les recomiendo revisar más al respecto de este proyecto, porque está muy interesante ver su funcionamiento. Ahora, esto no será un tutorial como tal, más que nada mi enfoque es mostrarles este mundo tan interesante e invitarlos a que se sumen a este grupo de personas que estudian o intentan mejorar el mundo de las redes neuronales.
Porqué escogí generar música?
El tema principal en el que he estado interesado es la generación de música, pues es algo más novedoso si lo comparamos con la modificación de imágenes, desde hace tiempo anhelaba realizar un proyecto sobre la generación de música, más que nada porque los modelos que pueden utilizarse son muy interesantes y divertidos de poner en práctica, sobre todo utilizas muchas herramientas interesantes que mencionaré más adelante. Comencé buscando proyectos relacionados a lo que quería desarrollar. Debo decir que al principio de este proyecto, originalmente la idea que tenía en mente era generar música de Star Wars, así que empecé mi búsqueda por el sagrado y vasto mundo de Google, encontré dos proyectos bastante interesantes y útiles, en uno utilizaban un modelo muy complejo, C-RNN-GAN (Continuous Recurrent Neural Network Generative Adversial Model), y se basa en un artículo publicado por un estudiante, este proyecto lo pueden revisar aqui Este blog y repositorio fueron hechos por olofmorgen les recomiendo checar su GitHub y ver sus proyectos son muy interesantes, pero al intentar estudiar el modelo, me di cuenta que era bastante complicado a lo que yo quería lograr, pues aún me faltaba comprender algunos conceptos. Así que decidí buscar otro modelo llamado LSTM, este lo encontré en un post el cual generaba música de videojuegos y me pareció bastante interesante usarlo en el proyecto que quería desarrollar.
Un poco de explicación.
Ahora antes de comenzar debemos entender un poco de terminología y entender algunos conceptos sobre redes neuronales que serán necesarios entender por lo menos a un nivel superficial.
Redes Neuronales Recurrentes
Una red neuronal recurrente trabaja en ciclos de retroalimentación de datos, al momento de ir avanzando durante los pasos o épocas (epochs) de entrenamiento la información persiste. Los humanos no comienzan a pensar desde cero cada segundo. A medida que lees este blog, comprendes cada palabra en base a tu conocimiento de las palabras previas, no olvidas todo y comienzas a pensar desde cero nuevamente, es decir que tus pensamientos tienen persistencia.
Redes tradicionales no tienen este beneficio lo cual podría considerarse un gran defecto, por ejemplo, digamos que ves una película y quieres clasificar cada punto de esta, una red neuronal no podría razonar puntos previos de la película para informar de los nuevos puntos, es por ello que recurrimos a utilizar redes neuronales recurrentes. En el siguiente diagrama podemos observar cómo funciona una red neural recurrente:
Imagenes obtenidas en el blog de colah, proporciono el vinculo en la seccion de agradecimientos.
"X_t" representa un grupo de datos que entran a una parte de la red neuronal "A" y surge un resultado "H_t" o como es llamado normalmente: "output". El ciclo permite que esta información sea mandada de una parte de la red a otra. Desarrollando el diagrama anterior tenemos lo siguiente:
Esta representación de red neuronal recurrente es como una cadena de redes, ¿se ve más intuitivo no? Las redes recurrentes desde un punto de vista práctico son algo muy íntimamente relacionado con listas y secuencias. Lo más sorprendente es que esta idea es vieja, la primera persona que llegó a mencionar estas ideas data del año 1986, el problema era que en esos tiempos las máquinas no daban para tanto poder de programación, aún en estas fechas para proyectos muy grandes a veces necesitas una computadora que sea muy potente. Pero aun así se han creado proyectos bastante increíbles con estas redes como: reconocimiento de voces, modelado de lenguaje, traductores, etc. De hecho, hay un artículo que habla sobre los resultados de gente que ha trabajado con estas redes se las recomiendo.
El problema a largo plazo de las redes neuronales recurrentes
Una de las cosas más llamativas en cuanto a redes recurrentes es cuando se quiere hacer una conexión entre información pasada e información presente, por ejemplo querer predecir la siguiente palabra dado una serie de palabras en un texto como "Mi camisa es de color azul" no requiere de mucho contexto, el problema se presenta cuando quieres hacer algo como "Mi familia es de México...por eso hablo español", el objetivo en este caso es querer indicar que el idioma hablado es español, pero si queremos reducir las posibilidades y encontrar la palabra "español" debemos tener más contexto, específicamente que es de México. Desafortunadamente entre más crezca la información, más difícil será para la red aprender a conectar la información.
La teoría establece que una red recurrente podría resolver este tipo de problemas, pero solamente si el programador escoge perfectamente los parámetros, ¡afortunadamente las LSTM no tienes estas limitaciones!
LSTM (Long Short Term Memory)
Estas redes fueron creadas explícitamente para resolver los problemas ya descritos anteriormente de las redes recurrentes, pero ¿cómo es que funcionan? Y ¿cuáles son las diferencias entre las dos?
Una red recurrente y una LSTM tienen el diseño de cadena antes mostrado, la red recurrente normalmente tiene una estructura bastante simple como una simple capa tanh, mientras que la red LSTM tiene una estructura más compleja, pues dentro de cada módulo tiene cuatro capas que interactúan de una manera muy especial.
Lo principal en las LSTM es un estado de cada celda o "cell state" (C_t), esta es la línea horizontal que corre en la parte superior, piénselo como una cinta transportadora la cual lleva los cell states al final con cambios mínimos, la LSTM puede hacerle cambios a los cell states, regulado por algo llamado "gates" o compuertas, las cuales se usan para opcionalmente dejar pasar información. Están compuestas por una capa de red neuronal sigma y una operación producto-punto, La sigma envía un valor entre 0 y 1, los cuales indican la cantidad de componentes que se van a dejar pasar, donde el valor 0 indica que no se dejan pasar componentes. Los LSTM tienen tres de estas compuertas para proteger muy bien la información del cell state y, por supuesto, también cuentan con una compuerta tanh, esta compuerta resuelve el problema del desvanecimiento de gradiente. El objetivo es encontrar una función cuya segunda derivada pueda sostenerse por un largo tiempo sin llegar a cero. Cada compuerta cuenta con una función de activación ya sea sigma o tanh (tangente hiperbólica), esto es una ecuación matemática, la cual determina la salida (output) de una red neuronal y se añade a cada neurona de la red determinando si esta es activada o no, basándonos en si la entrada (input) de cada neurona es relevante para la predicción del modelo o si no lo es. Ayudan a normalizar la salida de cada neurona a un rango entre 0 a 1 o -1 a 1.
En este modelo se utilizaron funciones de activación ReLU y softmax, más abajo explico sus ventajas y desventajas. Existen otras funciones que podría usar:
Función sigma/logística: esta previene saltos en los valores de salidas y tiende a tener predicciones claras cuando X es mayor a 2 o menor a -2, pero su computación es muy costosa.
Función tangente hiperbólica: es muy similar a la función sigma pero su principal diferencia es que es una función "zero centered", es decir que la media de esta función será cero, lo que ayuda a que se tenga una convergencia rápida.
Leaky ReLU: resuelve el problema de la ReLU tradicional agregando una pequeña inclinación positiva en el área negativa para permitir backpropagation incluso para valores negativos, el problema es que no da predicciones consistentes para valores negativos.
Parametric ReLU: introduce la inclinación de la parte negativa como argumento. Por lo tanto, es posible hacer backpropagation para aprender el valor de alpha más apropiado, el problema es que se puede desempeñar muy diferente para otros problemas.
Swish: es una nueva función de activación automática descubierta por los investigadores de Google, se cree que puede desempeñarse mejor que una ReLU con una eficiencia computacional similar, pueden leer más al respecto en este articulo.
Recientemente se está buscando una manera de automáticamente aprender cual es la función de activación óptima para cierta red y hasta automáticamente combinar funciones para obtener una precisión optima.
Para una explicación más detallada del funcionamiento de las LSTM les recomiendo que vean el blog de colahaqui
Music21
Lo que hace este proyecto es leer la música en formato MIDI usando music21, se extraen las notas de los archivos MIDI con los que se quiere aprender para generar música similar.
Music21 es una colección de herramientas que facilita a las personas la obtención de respuestas sobre música de forma eficaz y sencilla. Por ejemplo, dudas como: "Me pregunto cuántas veces Bach hace eso", "desearía conocer cuál fue la primer banda en usar ese progreso de acordes" o dudas como la mía, es decir, si quieres crear un programa el cual automáticamente genere más música como es mi caso.
Keras
Es una API de redes neuronales de alto nivel que simplifica interacciones con Tensorflow, se creó con el enfoque de poder realizar experimentaciones rápidas. Se utilizan Keras para poder crear y entrenar el modelo LSTM, cuando el modelo es entrenado se utiliza para generar notación musical para nuestra música.
Música Utilizada
En el proyecto original utilizan música de Final Fantasy para entrenar su red. No he tenido la oportunidad de jugar todos los juegos de Final Fantasy, solamente el tercero, por ello decidí utilizar música de Final Fantasy 3, Chrono Trigger, Mario bros 3 y The Legend of Zelda: Ocarina of Time. La música fue encontrada en una página llamada VGMusic, la cual contiene una variedad de música de videojuegos en formato midi y tiene su propia sección de midis que sólo utilizan el piano lo cual fue muy útil. Lamentablemente no tuve éxito en mi búsqueda sobre canciones de star wars en formato midi, pues solo eran de piano, lo que hacía un poco más difícil la idea de utilizarlo como datos de entrenamiento.
El Modelo
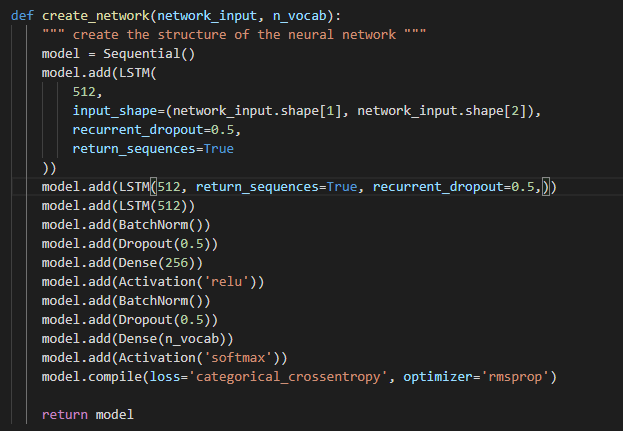
Ahora entraremos con el funcionamiento del programa, ¿qué es lo que está pasando en el código? Bueno, primero empieza obteniendo la música en formato midi y utilizando Music21 para convertir las notas de la música a datos que son más manejables por el programa, los guarda en un archivo llamado "data/notes", esto lo hace cada vez que corres el programa así que si cambias la música en tu carpeta "midi" volverá a convertir esa música en datos para poder entrenarla. Ahora, lo siguiente que hace es preparar las secuencias que serán usadas por la red neuronal obteniendo todos los "pitch names" de las notas que ya obtuvimos, crea un diccionario y mapea los pitches a enteros, después de esto crea secuencias de entradas y sus salidas correspondientes, las entradas se reforman para algo más compatible con capas LSTM y normaliza las entradas. Ahora se crea la estructura de la red neuronal y al final entrenamos nuestra red.
En este modelo se usaron 4 tipos de capas distintas:
Capa LSTM: Toma una secuencia como entrada (input) y puede devolver una secuencia o una matriz.
Capa dropout (expulsar): Esta capa consiste en ajustar una fracción de entradas a 0 en cada actualización durante el entrenamiento para prevenir sobreajuste (overfitting), la fracción de entradas se determina por el parámetro usado con la capa.
Capa densa o Capa completamente conectada (fully connected): Es una capa de red neuronal donde cada nodo de entrada (input) está conectado con cada nodo de salida (output).
Capa de activación: Determina qué función de activación nuestra red neuronal usará para calcular el nodo la salida (output) de un nodo.
Ahora que conocemos un poco de cada capa es hora de introducirlas a nuestra red neuronal. Para cada capa LSTM, densa y de activación el primer parámetro indica cuántos nodos la capa debe tener, en la capa dropout es la fracción de entradas (inputs) que se "soltarán" durante el entrenamiento. Para la primera capa debemos introducir un valor único llamado "input_shape", el cual se usa para informar a la red sobre los datos que está entrenando.
Como expliqué en la sección de LSTM, cada compuerta cuenta con su función de activación, en este modelo se utilizaron funciones ReLU y softmax, cada función tiene sus ventajas y desventajas, por lo que debes escoger las que mejor se ajusten a tu proyecto. Se usó ReLU (Rectified Linear Unit) ya que le permite a la red converger rápidamente y aunque la gráfica de esta función puede verse como una función lineal, su función derivada permite hacer "backpropagation", mientras que softmax permite manejar múltiples clases normalizando las salidas de cada clase entre 0 a 1 y divide por su suma, típicamente softmax es usado solamente para la capa de salida en redes que necesitan clasificar entradas a múltiples categorías.
Me basé en el trabajo realizado por Sigurður Skúli para ir desarrollando el mío, me base en su trabajo de generación de música para hacer las modificaciones necesarias para realizar el proyecto que tenía en mente.
En cuanto a mi entrenamiento, hice unas pruebas con el pipeline cambiando batches. Inicié con un batch de 32 al correr las primeras canciones con epoch de 150 para hacer pruebas rápidas, pero con 32 me generaba resultados que no eran de mi agrado o el tipo de música que buscaba, así que fui a 64 y el número de epochs a 250, pude haber aumentado el número a algo más alto para ver los resultados, pero debo decir que es un poco más tardado hacerlo. Mi plan a futuro es hacer entrenamientos con epochs más largos para hallar un punto donde sienta que es muy razonable el cambio o que la pérdida será mínima. Mucho de mi enfoque se centró en cambiar las capas: la cantidad de capas y la cantidad de neuronas por cada capa.
Un defecto que tiene ahorita el código es que cuando termina el entrenamiento te genera un numero de archivos hdf5 igual al número de epoch, el título de este archivo tiene el número de epoch y la pérdida, y cada vez que corras el predict.py para generar una nueva canción debes cambiar el archivo que busca al nuevo archivo hdf5. Esto a mí no me gustaba ya que es muy incómodo así que lo cambie para que el nombre del archivo no deba cambiarse.
Dato curioso: Normalmente el entrenamiento utilizando la supercomputadora de la Universidad de Sonora ACARUS me tomó alrededor de 3-4 horas con 250 epochs.
Resultados
Los primeros entrenamientos que hice solamente utilizaban música de cada juego por separado, para ver qué resultados me daban y al final utilicé toda la música que obtuve en una sola corrida para ver los resultados
Chrono Trigger
Aquí tuve algunos problemas con las primeras dos corridas porque fue cuando estaba experimentando con el tamaño del batch, en el último resultado volví a batch de 64 y siento que los resultados fueron mejores, si han jugado Chrono Trigger podrán ver las similitudes con las piezas originales, aquí la menor perdida fue de 0.027 con el epoch 243.
Chrono Trigger con 100 epoch
Chrono Trigger con 150 epoch
Chrono Trigger con 250 epoch
Mario Bros
Al iniciar el entrenamiento con esas canciones, pensé que los resultados no serían muy buenos, pero al concluir las canciones que generó note que fueron bastante buenas y algunas de mis favoritas. Para personas que ya han jugado estos juegos clásicos verán muchas similitudes con sus contrapartes originales, aquí la menor perdida fue de 0.024 con el epoch 248.
Mario Bros 3 con 100 epoch
Mario Bros 3 con 150 epoch
Mario Bros 3 con 250 epoch
Legend of Zelda: Ocarina of Time
En este punto esperaba mucho ya que la música de este juego es muy buena en mi opinión y no me defraudó el programa la música quedo bien y en particular la segunda es muy similar a una canción del juego, aquí la menor perdida fue de 0.029 con el epoch 248
The Legend of Zelda con 100 epoch
The Legend of Zelda con 150 epoch
The Legend of Zelda con 250 epoch
Combinación de toda la música
No sabía que esperar de estos resultados, pensaba que no quedarían tan bien las canciones y que quizá haría una canción bastante mala lo dejo a criterio de todos como quedo, tuvo una pérdida de 0.8 en el epoch 250
Conclusión
Al final de todo me siento muy satisfecho con los resultados que me dio el proyecto, se pudo observar que al momento de ir aumentando los epoch las canciones que se generaban iban mejorando y nos daban ritmos que tenían más sentido con el resto de la canción, mis primeros entrenamientos los hacia con epoch de 50 - 100 y observaba que a veces me daba resultados muy buenos, pero solo en pequeñas porciones de la canción y en epoch grandes las canciones tenía más congruencia en total. Me siento satisfecho con el trabajo que he realizado sobre el tema de las redes recurrentes y machine learning, pues están en un punto muy temprano y emocionante. Aprendí bastante sobre sobre machine learning con este proyecto y me demostró porque esta área está creciendo bastante y lo divertido que puede ser al ver tu proyecto empezar a correr y funcionar por primera vez, viendo los resultados de tus esfuerzos. Además de mucha teoría y conocimientos bastante útiles. Mis planes a futuro con este proyecto es agregarle algún tipo de UI (interfaz de usuario) para poder hacer que las canciones se generen de manera interactiva para el usuario y agregarle nuevos instrumentos al entrenamiento para no solo trabajar con un piano. Si quieren empezar probando el código pueden correr predict.py para que les genere algunas canciones y si quieren probar el entrenamiento pueden reducir el número de epochs a algo más razonable y moverles a los valores para ir entendiendo qué está sucediendo con el código, se los recomiendo. A todos los que lean este blog se los recomiendo y espero que encuentren un gusto como el que he encontrado yo. Todos los enlaces llevan a lecturas muy interesantes de personas que han hecho un esfuerzo y aunque no vayan a trabajar en esto les recomiendo estas lecturas y estudiar más del tema, se darán cuenta que mucho de la vida cotidiana utiliza redes recurrentes y machine learning en general.
Agradecimientos
A Sigurður Skúli por su blog sobre generación de música con LSTM, el codigo original también pueden hallarlo aquí.
A Christopher Olah por su post sobre redes recurrentes y LSTM me ayudo a entender bastante y por las imágenes que fueron obtenidas de su blog.
A la sección de funciones de activación de Missinglink por su guía de como escoger la mejor función de activación.
A el Doctor Julio Waissman por sus clases sobre redes neuronales y apoyo con dudas.
A la Profesora Sonia Sosa por su apoyo en cómo obtener la información y manejar mi método de trabajo, además de empujarme a poner lo mejor de mí en este proyecto.